Rating MCP Server Quality: How We Score Tools, Skills & Annotations
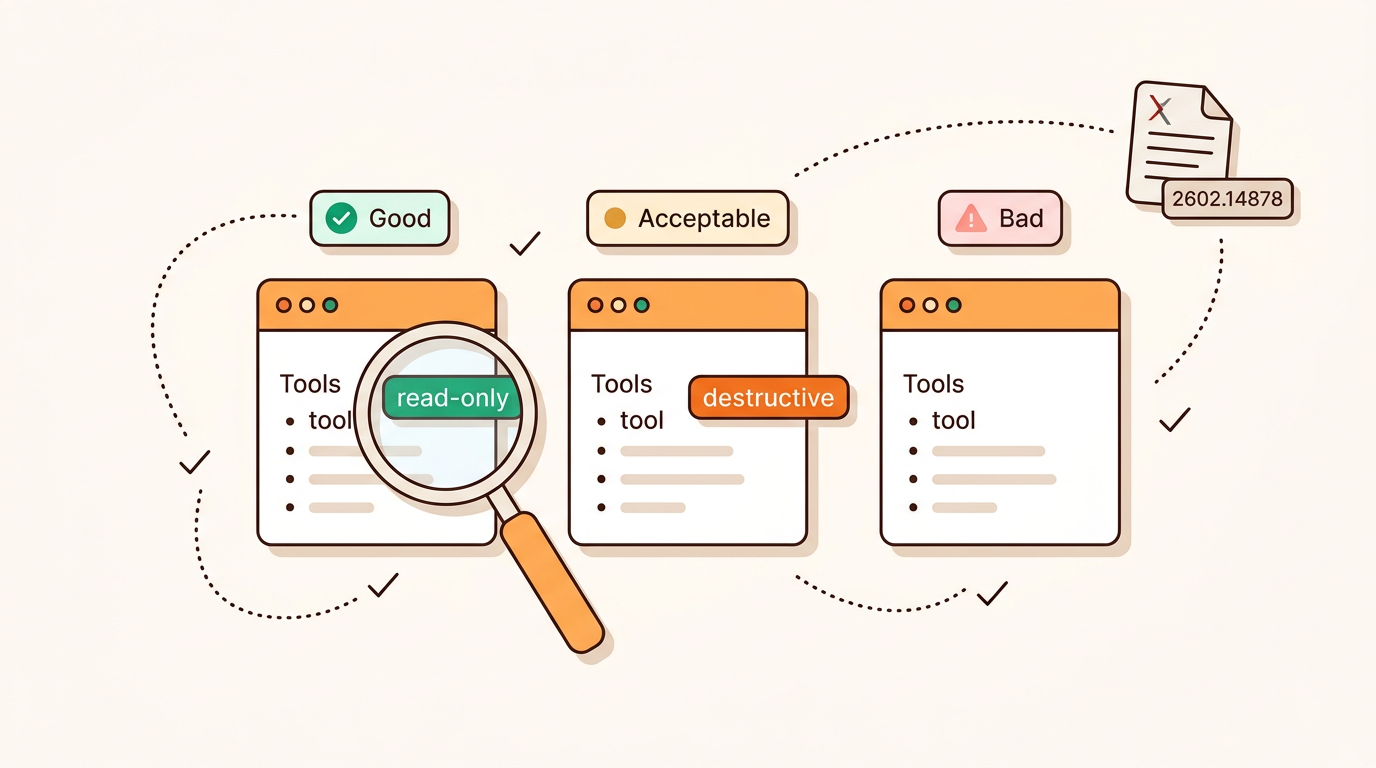
The average MCP tool description is bad. Two recent arXiv papers measured exactly how bad. 97.1% of analyzed tools carry at least one description smell. 73% of servers reuse the same display_name across multiple tools. In head-to-head selection between five functionally equivalent servers, the one with a clearer description gets picked 72% of the time vs a 20% baseline.
A 260% selection lift from prose alone is the headline. Descriptions aren't documentation; they're part of the agent-facing prompt, and a bad one quietly costs you every selection round your server is in. So we built a scorer.
MCPBundles now runs an LLM-as-judge rubric over every published server, covering tool descriptions, server-level skill content, and the structured MCP annotations that the runtime actually reads. The verdict shows up on the public listing page.






